 Previous Topic
Previous Topic
Managing In-Memory Cubes
In-memory cubes cache aggregations (pre-computed aggregate functions) of business views. This topic describes how you can create, use, and manage in-memory cubes, as an administrator.
You can use the cube data to improve the performance of reports and visualizations, when you analyze and visualize data from any data source, including relational, cloud, and big data sources.
You can generate and update in-memory cubes by scheduling cube tasks. Similar to scheduling report tasks, you can schedule to generate in-memory cubes immediately, at a specific time, or periodically to fetch the data from the DBMS and store it in Report Server. After Server creates an in-memory cube and it is ready for use, all reports, library components, and visual analysis that use the same business view as the in-memory cube will automatically use the cube rather than go to the database for the data. By applying in-memory cubes, your reporting performance will be greatly improved.
This topic contains the following sections:
- Creating In-Memory Cubes
- Viewing and Managing the Cube Tasks
- Recovering In-Memory Cubes
- Synchronizing In-Memory Cubes With Catalog Republish
Creating In-Memory Cubes
A business view can have only one in-memory cube. When a business view contains parameters, its in-memory cube can only represent the data of one parameter scenario.
Via Server's scheduling mechanism, you are able to define when to create an in-memory cube for a business view and when to update it at a specific time or periodically. This is especially useful for month and quarter end reports where multiple reports use the same dataset with the same parameters such as begin and end date.
In-memory cubes have no versions: once they are updated, Server keeps only the latest ones for the business views.
To create an in-memory cube:
- On the system toolbar of the Server Console, navigate to Administration > Configuration > Cache > Cube. Server displays the Cube page.
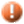 If it is the first time you create in-memory cubes, you need to first configure the maximum memory allowed for all in-memory cubes. To do this, select Configuration on the task bar of the Cube page (this option is not available to organization admins), then in the Maximum Cube Memory Allowed text box, specify the allowed maximum cube memory size in megabytes. The total allocated memory for each cube cannot exceed this value. It does not take into consideration the actual memory used by the in-memory cubes or if some of the cubes are swapped to disk. This value should not be larger than 80% of your Java Heap size.
If it is the first time you create in-memory cubes, you need to first configure the maximum memory allowed for all in-memory cubes. To do this, select Configuration on the task bar of the Cube page (this option is not available to organization admins), then in the Maximum Cube Memory Allowed text box, specify the allowed maximum cube memory size in megabytes. The total allocated memory for each cube cannot exceed this value. It does not take into consideration the actual memory used by the in-memory cubes or if some of the cubes are swapped to disk. This value should not be larger than 80% of your Java Heap size. - Select New Cube on the task bar. Server displays the New Cube dialog box.

- Select the ellipsis button
 next to the Select a Folder text box.
next to the Select a Folder text box. - Server displays the Select Folder dialog box. Browse to the folder that contains the required catalog and select OK.
- From the Select a Catalog drop-down list, select the required catalog in the specified folder.
- In the Select Business View box, select the business view on which to create the in-memory cube. Server uses the business view name as the name of the in-memory cube.
- Select OK to confirm the selection. Server displays a new dialog box for defining the schedule task.
- In the General tab, do the following:
- Specify the parameter values if the business view uses parameters.
- Expand the Cube Information section by clicking the down arrow on the right.
- Select a priority to the task from the Priority drop-down list. The priority levels are from 1 to 10 in ascending order of lowest priority to highest priority. By default, Server ignores this property unless you modify the file server.properties to set queue.policy not equal to 0.
- Expand the Advanced section to configure advanced settings.
Specify the DB user and password with which to connect to the data source. You can either use the default ones defined in the catalog or specify another DB user and password.
- Select Add TaskListener to be Invoked to call a Java application before/after the task runs to obtain information about the task (for more information, see Applying TaskListener).
- If you are in a Cluster environment, you can also directly specify an active server in the cluster to perform the schedule task via the Specify a preferred server to run the task option.
- If you want to enable task recovery, select Enable Auto Recover Task. Then specify the maximum number of times to retry running the task in order to recover it, the time interval between the retries, and whether to recreate all or just the failed results.
- In the Schedule tab, specify the updating policy of the in-memory cube.
- In the Time tab, specify the time for when Server performs the task.
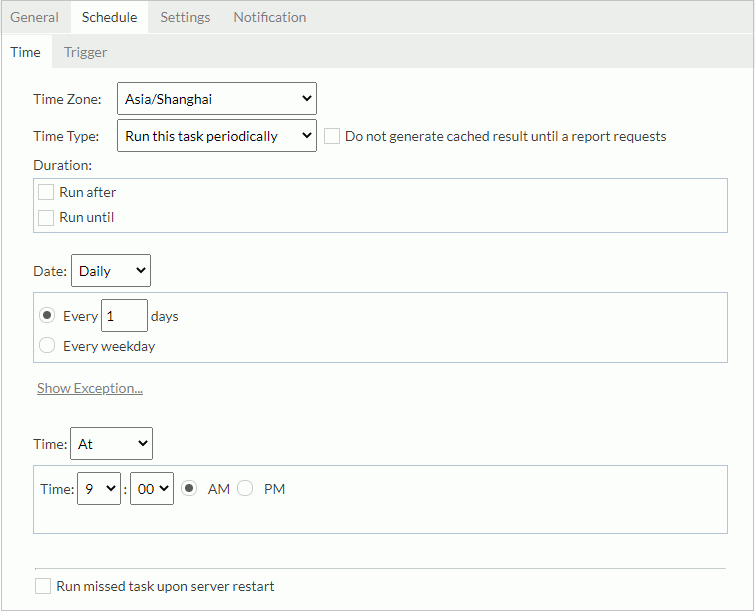
From the Time Zone drop-down list, select the time zone.
From the Time Type drop-down list, select when to run the task:
- To run the task as soon as you submit it, select Run this task immediately from the Time Type drop-down list.
- To run the task at a specified time, select Run this task at. Then define the date and the time.
- If you want to run the task repeatedly, select Run this task periodically. Then specify the duration, date, and time accordingly. By default, Server generates the in-memory cube according to the specified time condition. If you prefer to run the task only upon the first report running request after each scheduled time, select Do not generate cached result until a report requests. To add an exception date on which you do not want to run the task, select Show Exception, then select the Add button and in the Select Condition dialog box select the date. You can add several exception dates as you want. To remove an exception date, select it in the exception date box and select Remove.
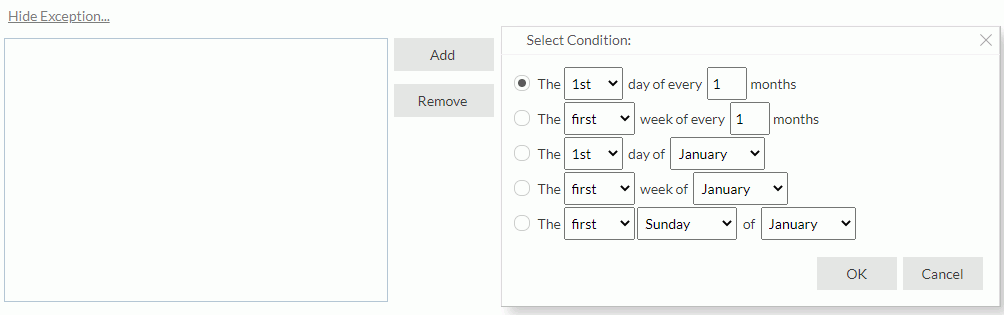
When you select to run the task at a specified time or repeatedly, you can select Run missed task upon server restart to run the missed tasks when you restart the server.
- If you want to bind a trigger to the task, select Trigger.
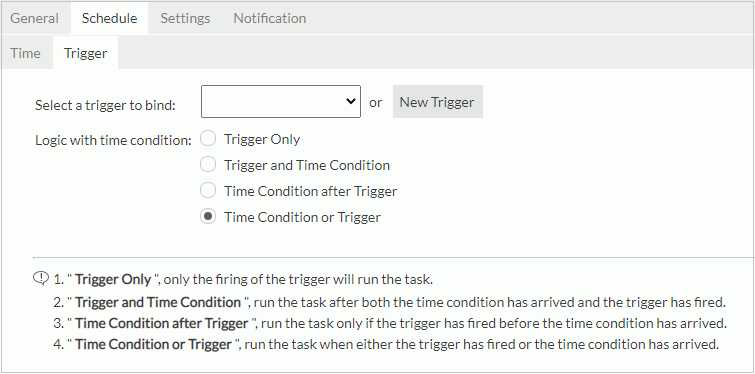
From the Select a trigger to bind drop-down list, select the required trigger or select the New Trigger button to create a new trigger in the New Trigger dialog box (the button is not available to organization admins), then specify the trigger logic with time condition.
- Trigger Only
Select if you want to perform the task only when the trigger is fired. - Trigger and Time Condition
Select if you want to perform the task when both time is up and the trigger is fired. When you selected this logic:
When you selected this logic: - No matter which condition is ready, Server performs the task only when its counterpart is ready.
- If you specify to perform the task at a specific time, you must select the option Run missed task upon server restart, otherwise Server regards the task as expired and deletes it when the time condition is ready before the trigger condition.
- Time Condition after Trigger
Select if you want to perform the task when time is up after the trigger is fired. If the time condition is ready before the trigger condition, the task will be regarded as expired and will be deleted. - Time Condition or Trigger
Select if you want to perform the task when either time is up or the trigger is fired.
- Trigger Only
- In the Time tab, specify the time for when Server performs the task.
- In the Settings tab,
configure the following settings:
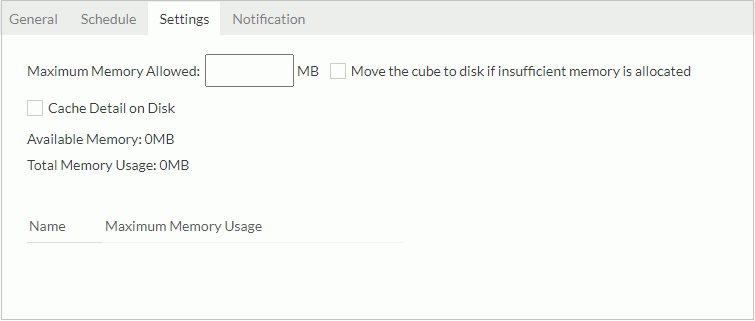
- In the Maximum Memory Allowed text box, provide a value for the cube. Otherwise, you cannot continue with the other tabs or to finish the dialog box.
- If you would like to cache the cube on disk once the available memory is exhausted, select Move the cube to disk if insufficient memory is allocated. If you do not select this option and the memory is not enough for the cube, Server will disable the cube and leave an error message in the log.
- If you would like to cache the detail data in the business view on disk, select Cache Detail on Disk. Otherwise Server only caches the aggregation data.
- In the Notification tab, specify to notify someone via email of when the task finishes or when it fails. Then in the mail box, type the information of the receivers and the mail contents. To send out mail notification, you should have predefined an email server first.
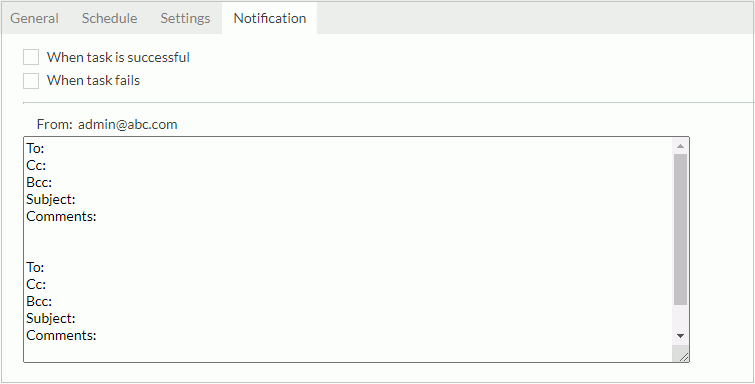
- Select Finish to submit the task. Server will then perform the task at the requested times to create in-memory cube for the specified business view.
After Server creates an in-memory cube and it is ready for use, all reports, library components, and visual analysis based on the same business view as the cube will automatically use the cube for retrieving data.
An in-memory cube freezes parameters in its related business view. If a report uses an in-memory cube and its business view contains parameters, when running the report, only parameters used in the report are available for specifying values and you cannot edit the business view parameters. In Report, a parameter may depend on another parameter; if the latter is frozen, the former will be frozen as well.
 Back to top
Back to topViewing and Managing the Cube Tasks
You can view information of the tasks scheduled for creating in-memory cubes and manage the tasks in the Schedule, Active, and Log tables in the Cube page.
Server displays all scheduled cube tasks in the Schedule table. You can edit any of the tasks in the table:
- To further edit the scheduling information of a task, select the row in which the task is, then select Edit > Properties on the task bar, or the Properties button
 on the floating toolbar, or right-click on the row and select Properties on the shortcut menu. Server displays a dialog box for you to edit the scheduling information. If you change the parameter values or schedule policy, they will only take effect after the next cube update; before that, all reports using the cube will still get the old data.
on the floating toolbar, or right-click on the row and select Properties on the shortcut menu. Server displays a dialog box for you to edit the scheduling information. If you change the parameter values or schedule policy, they will only take effect after the next cube update; before that, all reports using the cube will still get the old data. - To disable a task, select the row where the cube task is, then select Edit > Disable on the task bar, or the Disable button
 on the floating toolbar, or right-click on the row and select Disable on the shortcut menu.
on the floating toolbar, or right-click on the row and select Disable on the shortcut menu. - To enable a task, select the row where the cube task is, then select Edit > Enable on the task bar, or the Enable button
 on the floating toolbar, or right-click on the row and select Enable on the shortcut menu.
on the floating toolbar, or right-click on the row and select Enable on the shortcut menu. - To remove a task that is no longer required, select the row where the cube task is, then select Edit > Delete on the task bar, or the Delete button
 on the floating toolbar, or right-click on the row and select Delete on the shortcut menu.
on the floating toolbar, or right-click on the row and select Delete on the shortcut menu.
The Schedule table contains the following columns:
Server displays the cube tasks that have generated in-memory cubes which have data and are ready for use, in the Active table. You can edit the tasks here in the same way as you do in the Schedule table.
The Active table contains the following columns:
| Column | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | The name of the cube task. | ||||||||||||
| Catalog | The catalog that the cube belongs to. | ||||||||||||
| Data Source | The data source that the cube belongs to. | ||||||||||||
| Updated Time | The last time when the cube was updated. | ||||||||||||
| Allocated | The maximum memory allowed for the cube. | ||||||||||||
| Actual | The memory size currently used by the cube. | ||||||||||||
| Located At | The location of the cube:
|
||||||||||||
| Parameter | You see a parameter icon. After you select the icon, Server displays a dialog box to show all the parameters used in the cube. | ||||||||||||
| Usage | The number of reports and library components that have accessed the cube. If the number is bigger than 0, select it and you will get a detail table showing the information of all the web reports and library components that used data from the cube.
The detail table contains the following columns:
|
Server records all the events happened on all the cube tasks, in the Log table. You can delete any of the log records from the table if you want. To do this, select a record row and then select Edit > Delete on the task bar, or select the Delete button on the floating toolbar, or right-click on the record row and select Delete on the shortcut menu.
The Log table contains the following columns:
| Column | Description |
|---|---|
| Name | The name of the cube task. |
| Catalog | The catalog that the cube belongs to. |
| Data Source | The data source that the cube belongs to. |
| Activities | The type of the event:
|
| Start Time | The time when the event started. |
| End Time | The time when the event ended. |
| Status | The event status: Successful or Failed. |
| Message | Messages for failed events. |
Tips:
- You can customize the columns in the tables: switch to the table, select Preferences on the task bar of the Cube page, select the corresponding items in the Preferences dialog box, then select OK to apply the settings.
- You can sort the records in each table in the ascending or descending order by any column title. To do this, select on the underlined column title on which you want to sort the records. Server displays a sort icon right after the title, showing the sort direction.
Recovering In-Memory Cubes
If an in-memory cube is updating when Server shuts down, the cube will be disabled after the server restarts. You need to enable the cube task in order for the cube to continue to update at the next scheduled time.
Synchronizing In-Memory Cubes With Catalog Republish
After you republish a catalog, how the existing in-memory cubes based on the old business views in the catalog will be updated depends on the following conditions:
When no business view changed, the existing in-memory cubes are automatically applicable to the new catalog.
When a business view changed, the in-memory cube based on the old business view behaves as follows:
- Before the next schedule time, the cube cannot retrieve data to reports.
- When it is the next schedule time, Server fetches data from the new business view to generate an updated cube:
- If you added new parameters in the new business view, Server uses the default values until you specify new values to them.
- If you deleted old parameters from the new business view, Server removes the parameter values previously specified in the cube.
- If you changed the parameters and the previously specified values do not match the type, Server provides error messages in the server error log and disables the cube for service.